
 Over the last weeks, I started exploring XBRL, the eXtensible Business Reporting Language. Its purpose is “to improve the accountability and transparency of business performance globally, by providing the open data exchange standard for business reporting.”
Over the last weeks, I started exploring XBRL, the eXtensible Business Reporting Language. Its purpose is “to improve the accountability and transparency of business performance globally, by providing the open data exchange standard for business reporting.”
![]() There are clear parallels with IATI, the International Aid Transparency Initiative, the open data exchange standard for development and aid activities I have been working on.
There are clear parallels with IATI, the International Aid Transparency Initiative, the open data exchange standard for development and aid activities I have been working on.
In essence, the data collectors benefit more than the data publishers in both cases: what can we learn?
Founded in XML
The obvious commonality between IATI and XBRL is that they both have a technical foundation in XML, to define their grammar and to specify taxonomies.
But that’s not the interesting part: let’s look at their challenges in maturation and adoption.
A decade more experience
XBRL started about a decade before IATI, and has about twice the lifetime experience. XBRL is eXtensible, and specific profiles and taxonomies have been developed for particular use cases.
XBRL forms the basis of a number of standards across the world. Be it annual financial reporting, disclosing information in regulated markets such as stock exchanges, exchanging invoices, or reporting impact on Sustainable Development Goals or carbon footprints, such as through the Global Reporting Initiative, XBRL forms a foundational standard for many use cases: for both financial and impact reporting data.
XBRL-based formats have become mandatory in regulatory markets in North America (such as GAAP), the European Union (ESEF), and other areas around the world.
We have had similar discussions within IATI about additional, use-case specific guidelines and extensions to the standard.
Voluntary or mandatory?
At the recent Digital Reporting Convention, Professor Monika Kovarova-Simecek, Academic Director Economic and Financial Communications at the St. Pölten University of Applied Sciences, shared some very interesting insights from the world of XBRL.
My short version: XBRL’s key lessons show very similar experiences for anyone working in IATI. The first ~40 minutes will sound very familiar.
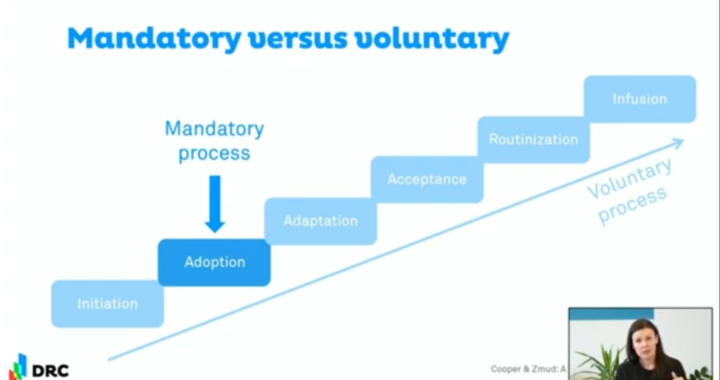
Professor Kovarova-Simecek’s explains voluntary versus mandatory adoption of technologies, based on Cooper and Zmud. She explains the difference between voluntary and mandatory adoption of technologies, such as an open data standard.
- In a voluntary process, there is a phase of initiation, in which an organisation considers the problem(s) to solve. From there, it will grow through various stages until eventually the technology is an integral part of everything.
- In a mandatory process, the initiation phase is skipped, so an organisation is handed the answer or solution, but they do not really know which question or problem it addresses. After adoption, there is no incentive to further integrate it into the organisation.
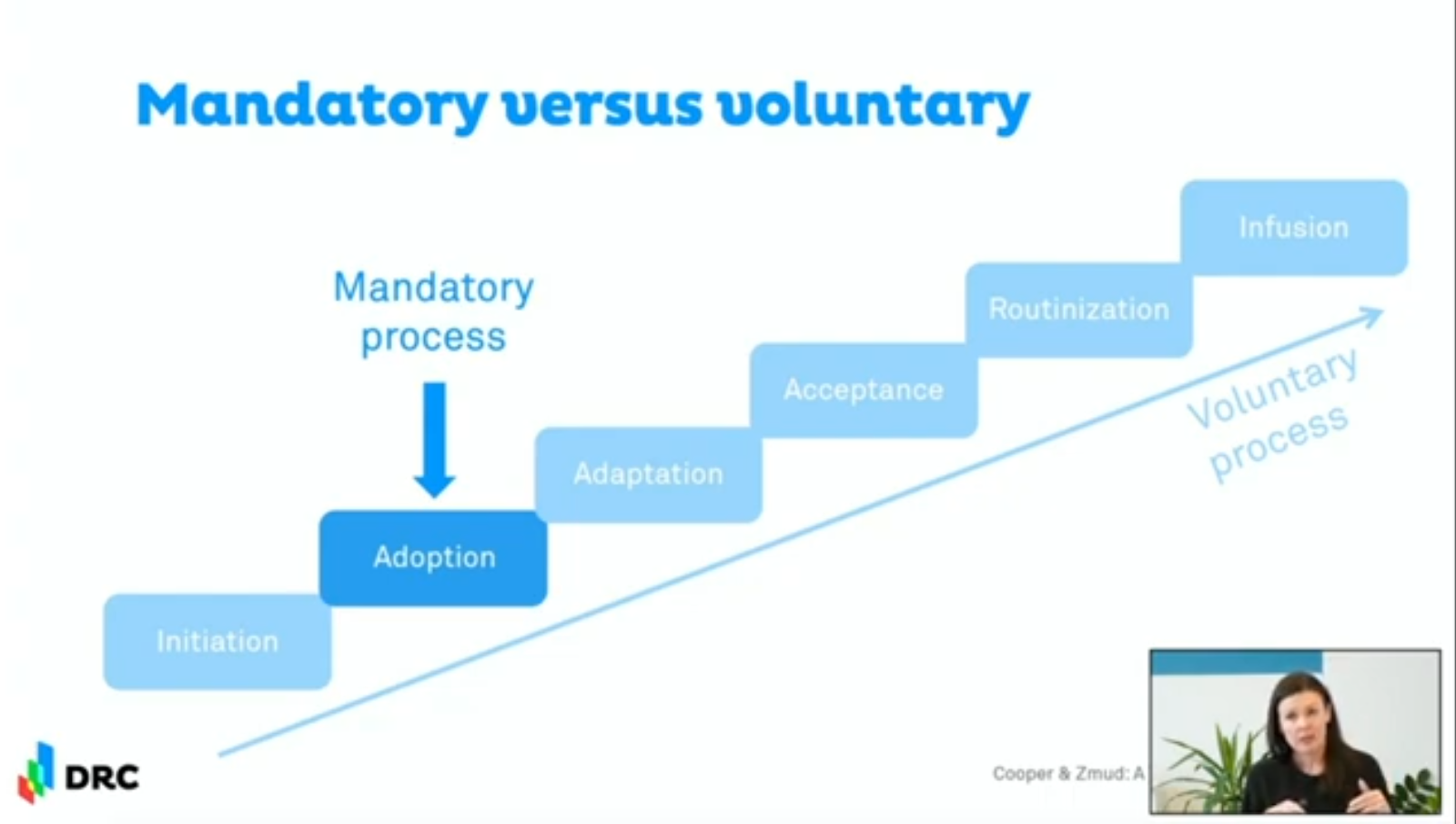
At the end of the day, it’s all about culture. A mandatory standard can increase “tactical adoption” in the short run, but few organisations will appreciate its “strategic value” in the long run.
It’s the same for IATI
It is a familiar experience for us, trying to convince organisations about the added value of IATI. In our training sessions with NGOs, and even in partnership networks of multiple organisations, there is a tension between the obligatory nature of having to publish (“report”) IATI data, and the hidden potential of replacing inefficient information exchange processes with simpler, more automated procedures.
There are technical parallels we can explore to guide IATI’s next steps. But more importantly, there are cultural parallels, and IATI can learn from the decade of extra experience that XBRL has had.
Sharing benefits and costs
On the one hand, it’s reassuring that another, even more widely applicable standard, has similar struggles. On the other hand, it’s sobering to see that also for XBRL, lots of individual publishers need to conform for the benefit of a few central authorities or entities. It is easy to see why collecting standardised data adds value, but it’s still hard to “give back” some of this added value to the data suppliers.
It is a reminder that sharing (open) data is not a symmetrical or zero-sum game: costs and benefits are currently not equally shared in the technical standardisation process.
- The mandatory nature of having to comply forces a lot of data publishers to invest as little as they can to meet the requirements.
- At the same time, data collectors want to invest as little as they can to harvest and use the data.
Towards a data eco-system
As a result, it is hard to develop and offer market-oriented services or products around the standard.
The XBRL ecosystem is ahead in its experiences. For instance, it offers certification of software to assure compliance with technical requirements. And, in The Netherlands, the Dutch Ministry of the Interior has recently decided to take control over the PEPPOL electronic invoicing infrastructure as a key component.
The lessons IATI can take from XBRL are around derivative standards for specific use cases; understanding the dynamics of mandatory standards; and the ecosystem of technical solution providers.
Looking forward to exploring more about XBRL.